



DeepSeek’s Chinese-style Innovation: A New Form of AI Economics (Part 2)
March 06, 2025
This insightful four-part series by CKGSB Professor Chen Long examines how DeepSeek, a trailblazer in Chinese-style AI, is redefining the economics of AI and scaling laws while setting new global benchmarks. From its unprecedented surge in daily active users to groundbreaking technological advancements and strategic execution, DeepSeek presents a compelling case study on the future of AI.
The series includes four parts:
PART 1|The arrival of a new global AI model with the highest daily active users
PART 2|What has DeepSeek achieved?
PART 3|How did DeepSeek accomplish this?
PART 4|What does the “DeepSeek Phenomenon” imply?
Stay tuned as we uncover how DeepSeek’s innovations are redefining the AI industry and shaping its global trajectory.
PART 2|What Has DeepSeek Achieved?
To fully understand the impact of DeepSeek on the AI industry, we must first clarify how it compares to the world’s leading large models. These large models can be categorized into pre-trained foundational models and post-training inference models. Overall, DeepSeek has already reached the level of the top large models in the United States in both of these areas.
01|A Comparison of AI large models in China and the United States
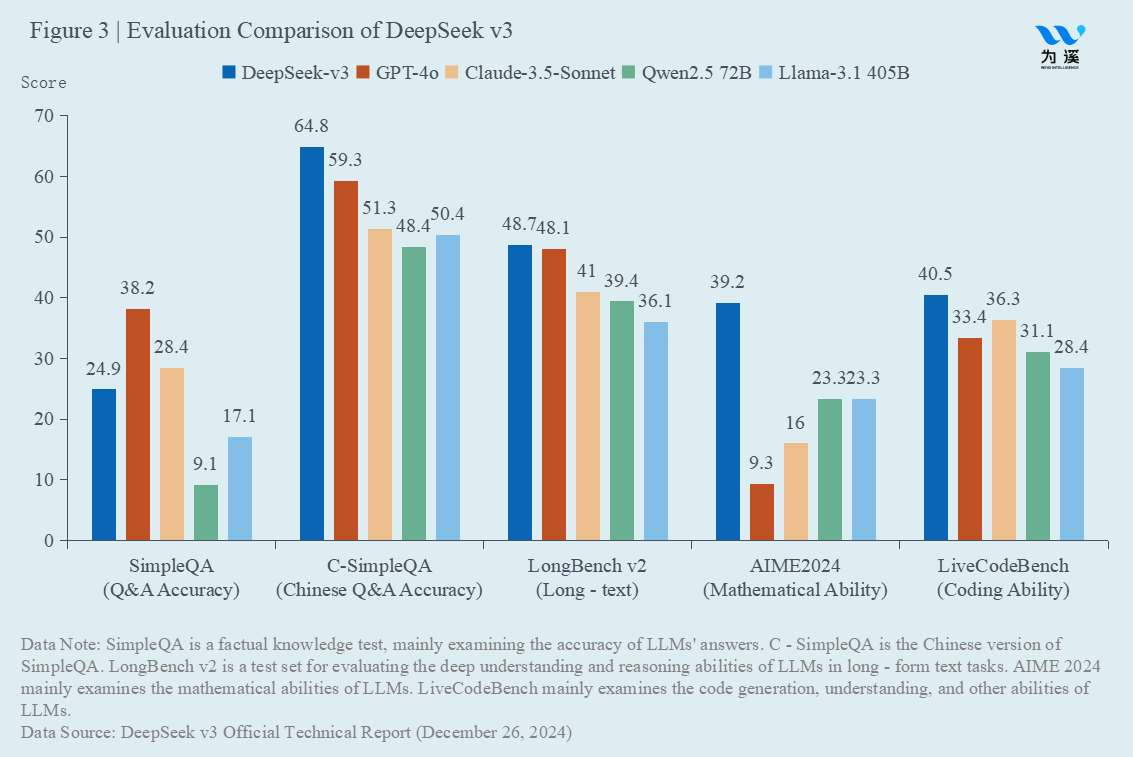
Let’s start by comparing pre-trained foundational large models based on textual data. DeepSeek’s relevant product is DeepSeek-v3. As shown in Figure 3, DeepSeek-v3 outperforms the two major U.S. large models, OpenAI’s GPT-4o and Anthropic’s Claude-3.5-Sonnet, across four dimensions: Chinese question-answering accuracy, long-text processing, mathematical ability, and coding ability. The only area where it lags is in factual knowledge question-answering accuracy. At the same time, as an open-source product, DeepSeek-v3 outperforms other open-source large models, including Qwen2.5 72B from Alibaba and Meta’s Llama-3.1 405B, across all these dimensions.
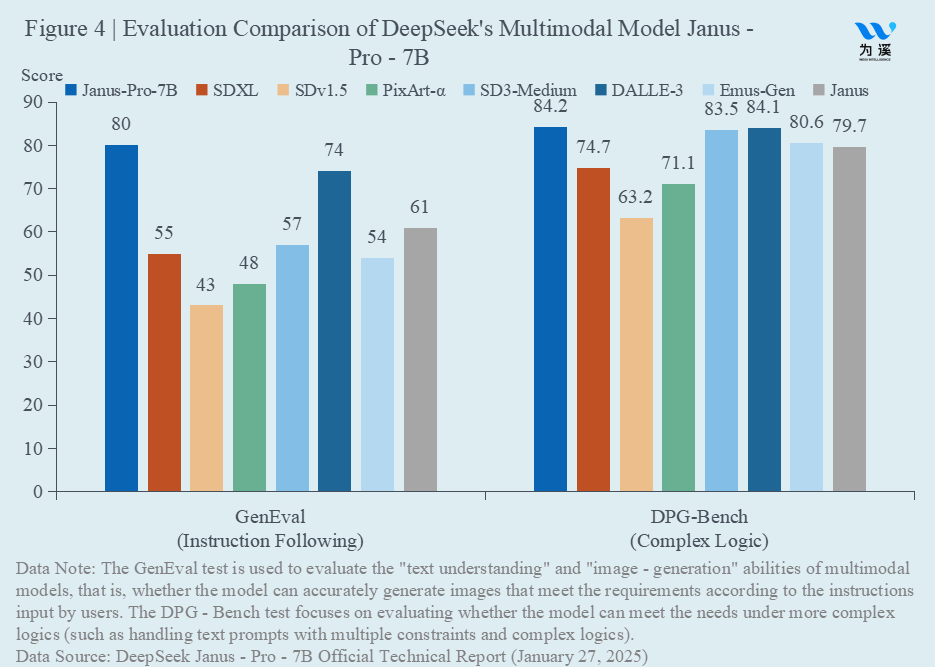
Next, let’s compare multimodal pre-trained foundational large models. DeepSeek’s multimodal model is Janus-Pro-7B. As shown in Figure 4, in the GenEval test, which evaluates such a model’s ability to follow instructions—i.e., whether it can accurately understand complex user inputs and generate images that meet the requirements—Janus-Pro-7B outperformed major comparable large models, including DALL-E 3 and Stable Diffusion. Similarly, in the DPG-Bench test, which evaluates a model’s ability to handle complex logic, i.e., whether it can process text prompts containing multiple constraints and complex logic to meet the required conditions, Janus-Pro-7B also surpasses its competitors.
What we have compared so far are pre-trained foundational large models based on text and multimodal data. This type of large model (e.g., GPT-4) is more effective in solving problems that don’t require deep thinking and can be answered by effectively matching information. To address more complex questions, however, it’s necessary to develop inference models that can break down the problem into reasonable “thinking chains” and perform deep thinking, based on the pre-trained model. After GPT-4, OpenAI realized that progress in intelligence requires deep thinking, and in 2024, they launched the post-training inference model OpenAI-o1.
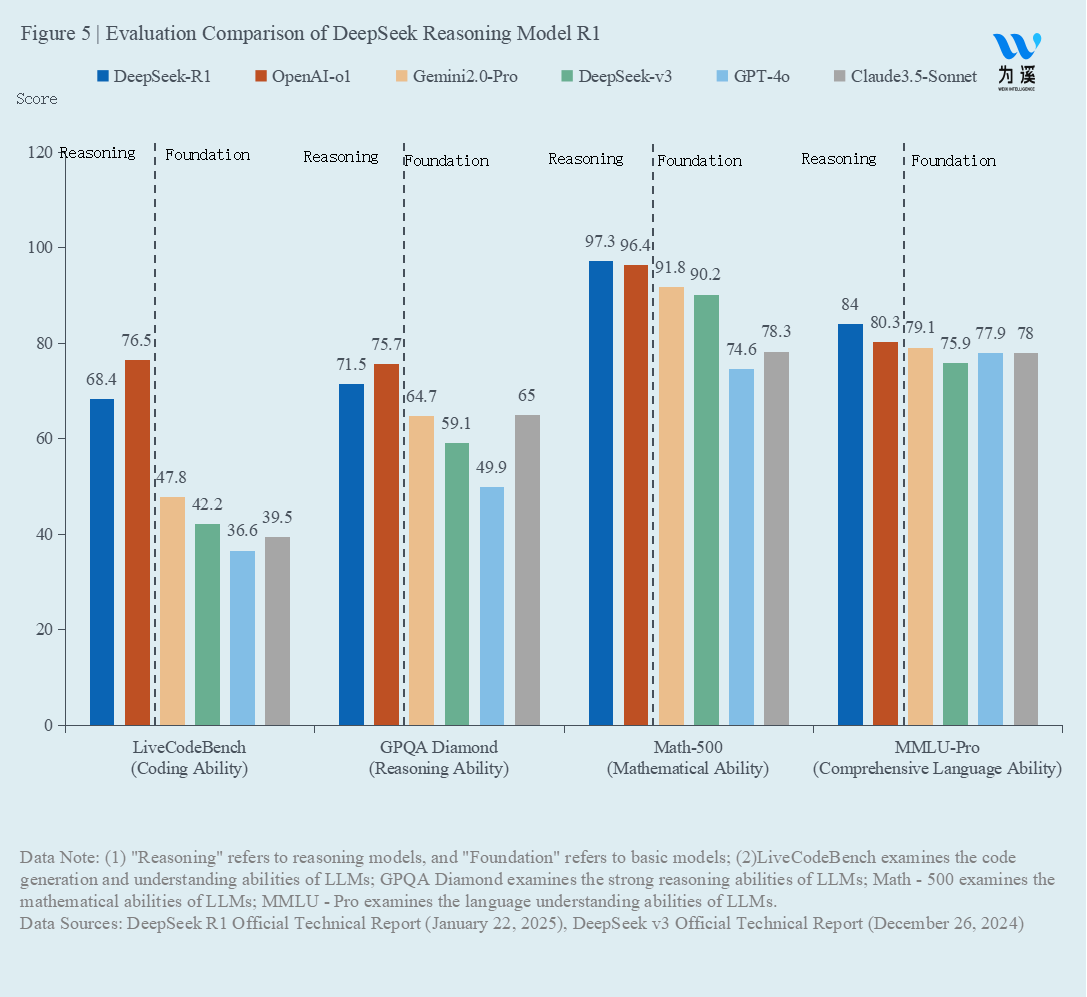
DeepSeek’s post-training inference model is DeepSeek-R1, which is the model most commonly used today. As shown in Figure 5, we can first observe that both OpenAI’s and DeepSeek’s inference models perform better than various pre-trained foundational models in coding ability, reasoning ability, mathematical ability, and overall language ability, illustrating the intelligence gains brought by deep thinking. Between DeepSeek-R1 and OpenAI-o1, the former lags behind the latter in coding ability and reasoning ability, but outperforms the latter in mathematical ability and overall language ability. The performance levels of the two models are considered close overall.
DeepSeek is not the only Chinese company catching up with top-tier American large models. Both The Economist on January 25, 2025, and former Google CEO Eric Schmidt in his recent comments have mentioned two Chinese large models: DeepSeek and Qwen. The latest pre-trained foundational model from Alibaba, Qwen2.5-Max, was released on January 29, 2025. As shown in Figure 6, in the latest evaluation, Qwen2.5-Max outperformed DeepSeek’s pre-trained foundational model, DeepSeek v3, in various assessments, including mathematical ability, reasoning, coding ability, and overall performance.
In summary, we can draw a groundbreaking conclusion: new Chinese AI forces, represented by companies like DeepSeek and Alibaba (with its Qwen model), have effectively caught up with the most advanced American large models in the fields of pre-trained foundational models and post-trained reasoning models. This indicates that the gap between American and Chinese large models is not widening but is, in fact, narrowing.
02 | “DeepSeek Phenomenon” – The Cost Efficiency Advantage
While Chinese large models have caught up with their U.S. counterparts, what is even more impressive is their cost efficiency advantage.
In January 2025, at the World Economic Forum in Davos, Microsoft CEO Satya Nadella candidly stated: “The performance of DeepSeek’s new models is impressive, particularly in model inference efficiency. We must take these developments from China seriously.”
As Nadella highlighted, the real breakthrough in cost made by Chinese large models is what is truly remarkable. According to DeepSeek, the training cost of their pre-trained model, DeepSeek-v3, is about $5.58 million, which reflects the computational cost during official training (i.e., GPU hours used during official training × H800 rental price per GPU hour × 55 days), but does not include the costs of initial architecture, algorithm research, and trial-and-error costs from ablation experiments. By comparison, Meta’s training of Llama 3.1 405B cost around $58 million (using over 16,000 NVIDIA H100 GPUs over 54 days). Meanwhile, Jensen Huang, CEO of NVIDIA, mentioned at the GTC 2024 that training a GPT model with 1.8 trillion parameters would require about 8,000 NVIDIA H100 GPUs over 90 days, estimating the training cost of GPT-4 at around $48 million. Additionally, Mistral AI founder Arthur Mensch revealed that the training cost of Mistral Large was under $22 million, and Anthropic CEO Dario Amodei disclosed that the training cost of Claude 3.5 Sonnet was in the tens of millions of dollars. By comparison, the pre-training cost of DeepSeek-v3 is about 1/10th that of top European and American models. Consistent with this, as shown in Figure 7, the API call price for DeepSeek-v3 is about 10% of that of GPT-4.
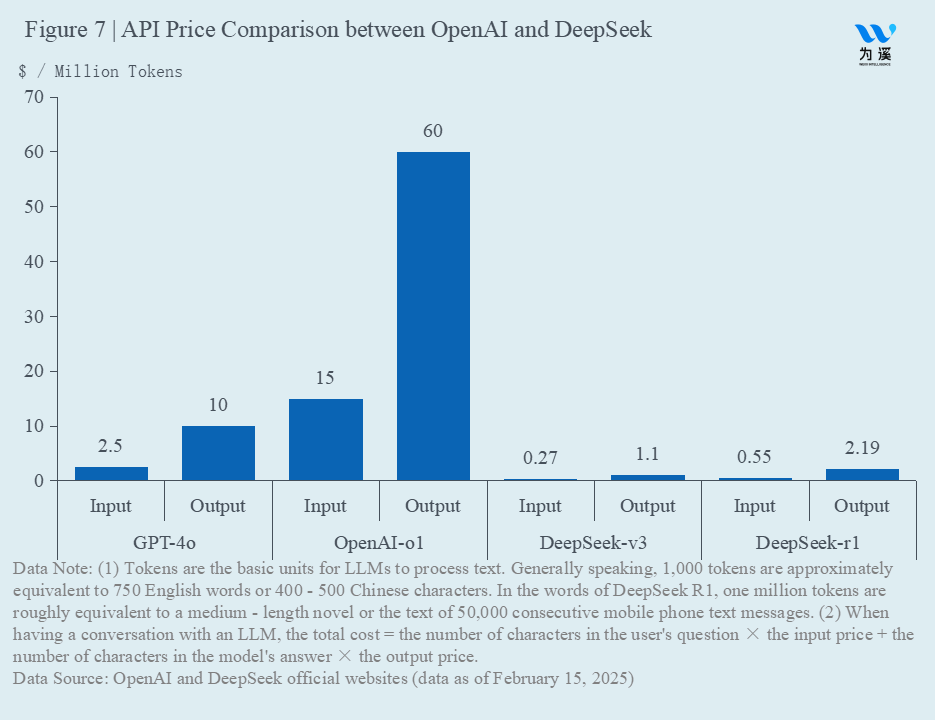
Now, let’s examine the training and usage costs of reasoning models. DeepSeek-R1 is trained based on the pre-trained model DeepSeek-V3. As we will explain later, whether using DeepSeek’s method to create a reasoning model or distilling a smaller model, the training costs are extremely low. For instance, the model distilled by Fei-Fei Li’s team, S1, cost only $50, humorously dubbed a “cup of coffee reasoning model”. In terms of usage, as shown in Figure 7, interestingly, the inference model of OpenAI (OpenAI-o1) has an invocation cost 6 times that of its pre-trained model (GPT-4o), while the invocation cost of DeepSeek-R1 is only twice that of DeepSeek-v3. This means the increase in the usage cost of DeepSeek’s reasoning models is much slower than that of GPT, resulting in the invocation cost of DeepSeek-R1 being less than 5% of OpenAI-o1’s.
From this, we can draw a second groundbreaking conclusion: Chinese companies have achieved a cost efficiency level such that the costs related to their models are less than 10 percent of those of top-tier American large models.
The combination of cutting-edge large models and significantly lower costs represents the most important new breakthrough demonstrated by DeepSeek, marking the entry of the AI industry into a new phase of growth and economies of scale. From an industrial landscape perspective, this breakthrough is disruptive.
Continue reading on CKGSB website
Enjoying what you’re reading?
Professor profile

CHEN Long
Professor of Managerial Practice in Finance, Cheung Kong Graduate School of Business (CKGSB)
PhD, University of Toronto
Related Articles



Related Articles




Our Programs

Asia Start: AI + Digital China Expedition
Asia Start provides entrepreneurs and executives with unparalleled access to Asia’s dynamic digital economy and its business ecosystems, offering the latest trends and insights, strategies, and connections to overcome challenges and unlock future growth for your business in Asia and beyond.
LocationChina (Shanghai, Hangzhou, Shenzhen)
Date11 - 14 May, 2026
LanguageEnglish

Scaling Innovation: AI and Digital Strategies for Business Transformation
Global Unicorn Program Series
In partnership with Columbia Engineering
This program is designed to equip senior executives with the strategic insights and tools necessary to lead in this transformative era.
LocationNew York, USA
Date27 Sep - 02 Oct, 2026
LanguageEnglish

Emerging Tech Management Week: Silicon Valley
Global Unicorn Program Series
In partnership with UC Berkeley College of Engineering
This program equips participants with proven strategies, cutting-edge research, and the best-in-class advice to fuel innovation, seize emerging tech developments, and catalyse transformation within your organization.
LocationUC Berkeley
Date01 - 06 Nov, 2026
LanguageEnglish

Stanford & Silicon Valley Immersion Program
Global Unicorn Program Series
In partnership with Stanford Engineering Center for Global & Online Education
This CKGSB program equips entrepreneurs, intrapreneurs and key stakeholders with the tools, insights, and skills necessary to lead a new generation of unicorn companies.
LocationStanford University Campus,
California, United States
Date06 - 11 Dec, 2026
LanguageEnglish with Chinese Translation


