



DeepSeek’s Chinese-style Innovation: A New Form of AI Economics (Part 3)
March 06, 2025
This insightful four-part series by CKGSB Professor Chen Long examines how DeepSeek, a trailblazer in Chinese-style AI, is redefining the economics of AI and scaling laws while setting new global benchmarks. From its unprecedented surge in daily active users to groundbreaking technological advancements and strategic execution, DeepSeek presents a compelling case study on the future of AI.
The series includes four parts:
PART 1|The arrival of a new global AI model with the highest daily active users
PART 2|What has DeepSeek achieved?
PART 3|How did DeepSeek accomplish this?
PART 4|What does the “DeepSeek Phenomenon” imply?
Stay tuned as we uncover how DeepSeek’s innovations are redefining the AI industry and shaping its global trajectory.
PART 3 | How Did DeepSeek Achieve This?
Before DeepSeek emerged, the world’s top large model companies were almost exclusively dominated by the U.S. A breakthrough by Chinese companies in this field was considered nearly impossible. However, the rise of DeepSeek not only disrupted this pattern, but also sparked a profound reflection on the essence of AI innovation. To understand DeepSeek’s innovation, we need to address the following key questions:
What is unique about DeepSeek’s innovation? Did DeepSeek find a new path to AGI, or does DeepSeek utilize special data, algorithms, or scenarios?
What lies behind the innovation offered by DeepSeek?
Is this innovation inevitable or accidental at this stage?
What does DeepSeek’s innovative capability signify?
01 | What Is Unique about DeepSeek’s Innovation?
At its core, DeepSeek’s innovation lies in engineering a cost-efficient innovation based on existing paths.
What DeepSeek is doing does not stay away from the path proposed by OpenAI: the foundational large model still follows the GPT-style pre-training approach, while the reasoning large model follows the post-training route centered on reinforcement learning. DeepSeek’s innovation, however, arises from engineering a cost-efficient innovation along these two established paths.
Let’s first explore DeepSeek’s innovation in the pre-trained foundational model. Within the original Transformer path, DeepSeek primarily optimizes in three areas: lower memory usage, smarter division of labor and collaboration, and more direct hardware interaction. Specifically:
- Lower memory usage is achieved through two main methods: first, MLA (Multi-head Latent Attention), and second, FP8 mixed precision training. The former can be understood as splitting a large matrix into the product of two smaller matrices during computation, with one of the matrices frozen after training. Small matrices are then used for inference, resulting in an exponential reduction in the computational demand. The latter can be understood as “precise calculation”, using FP8 where high precision is not required, and using FP16 or FP32 where higher precision is needed (larger numbers represent higher precision).
- Smarter division of labor and collaboration is achieved through the Mixture of Experts (MoE) model. For example, on the surface, DeepSeek-v3 appears to be a 671 billion-parameter foundational model, but in reality, due to effective division of labor among experts and an intelligent routing system, only 37 billion parameters (5.5% of the total) are activated in each calculation.
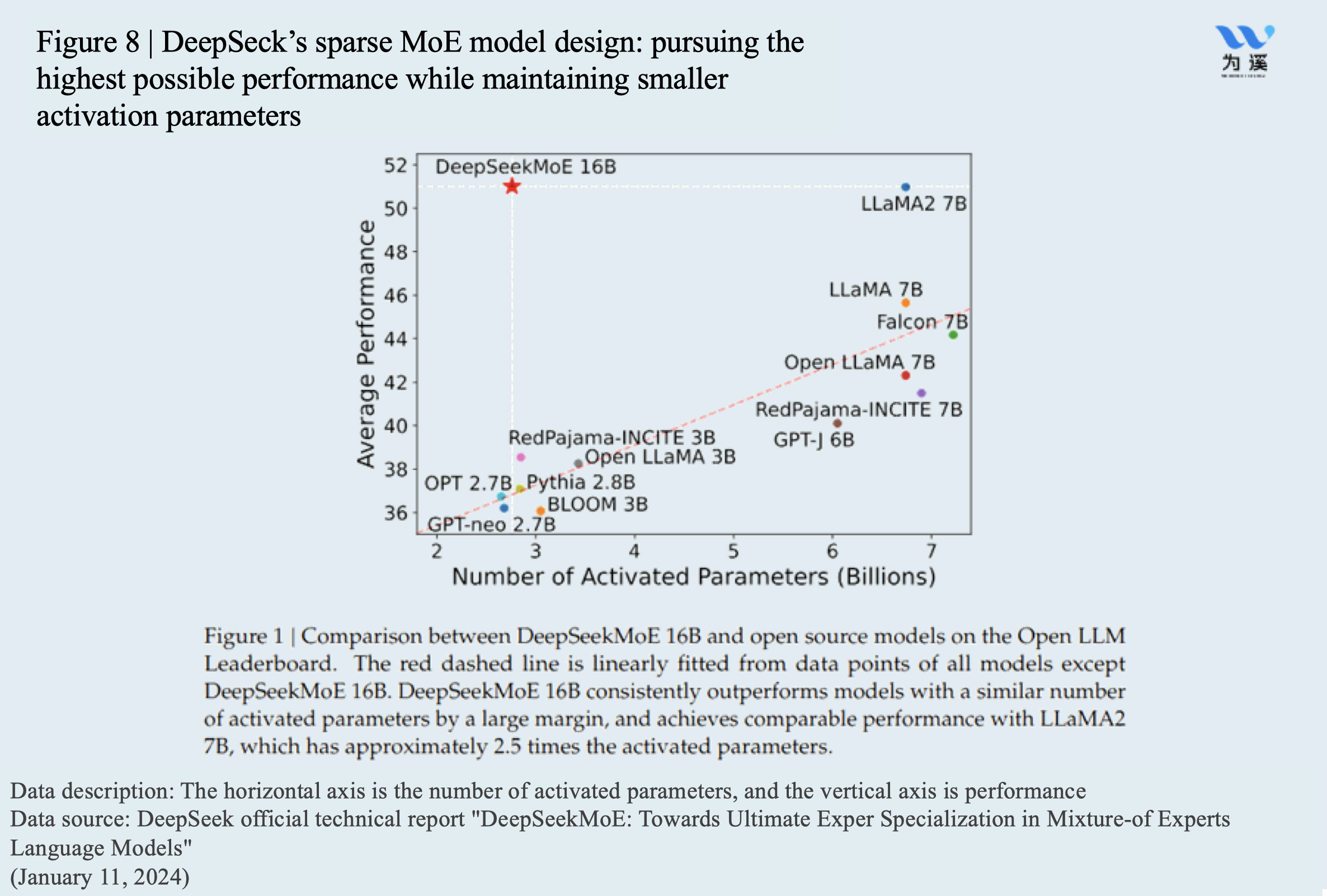
- More Direct Hardware Interaction: DeepSeek uses PTX (Parallel Thread Execution) instructions to directly adjust communication among NVIDIA chips. In the past, using PTX language was characteristic of quantitative traders, and few other fields used it directly. During the training of v3, DeepSeek modified 20 of the 132 streaming multiprocessors (SMs) to specifically handle server-to-server communication, rather than being responsible for computational tasks as well, thus improving the overall chip efficiency.
As seen, DeepSeek has significantly reduced its dependence on computational power and boosted computational efficiency through innovations in algorithmic efficiency and chip communication. This is the core reason behind the substantial reduction in computational costs compared to previous methods. This is the effect of engineering innovation and also a result of Chinese companies actively exploring ways to improve computational efficiency after facing restrictions on computational power from the West.
Now, let’s turn to DeepSeek’s innovation in reasoning models. DeepSeek found a simpler and more efficient path within OpenAI’s proposed framework for generating reasoning chains through reinforcement learning. Here’s how it happened:
OpenAI first hinted at the original concept for reasoning models:
- Initially, OpenAI revealed the “core secret” of reasoning models when it released the o1 model, explaining why it transitioned from pre-trained large models to post-trained reasoning models and the path it followed. OpenAI stated, “AI has been incredibly impressive in some areas, but reasoning abilities have been significantly lacking… When we completed GPT-4, the most intriguing question was: could we use the tool we created to teach the model to reason? We were greatly inspired by AlphaGo and have high expectations for reinforcement learning. In the training process of o1, we observed that when the model used reinforcement learning to generate and optimize its reasoning chain, its performance was even better than when humans wrote the reasoning chain for it.”
- However, most companies attempting to follow OpenAI’s lead struggled to make significant progress. Over the subsequent six months, AI labs worldwide tried to replicate o1 with very few successes. They faced challenges such as a lack of sufficient reasoning chain data, high costs in manual labeling, and so on. For instance, the previous open-source leader Meta Llama has not yet released its own open-source reasoning model, and its chief scientist, Yang Likun, publicly criticized OpenAI’s approach on Twitter that “OpenAI is not open enough.”
Building upon OpenAI’s ideas and drawing inspiration from AlphaZero’s training method, DeepSeek succeeded in training a reasoning model at an extremely low cost. The four key points of innovation are:
- First Innovation: DeepSeek diverged from the path that other large model companies were taking, which involved creating reasoning chain data and manual labeling. Instead, DeepSeek focused on the most logical fields, mathematics and coding, and required the model to provide “the expression of the thought process and the final answer” within a specified framework. By learning the correct answers, the large model autonomously generated reasoning chains and iterated on its reasoning abilities based on memory of past correct methods. First, since the training dataset consisted almost entirely of math and programming data, the logical processes were deterministic, and answers could be directly verified, effectively cultivating correct reasoning chains. Second, the format required the model to provide “the expression of the thought process and the final answer” in a specified box, similar to an exam. In contrast, traditional PPO architectures use a complex evaluation model to assess the accuracy, stability, and values of outputs, which is expensive to train, inefficient, and consumes memory during training.
- Second Innovation: Inspired by AlphaZero, DeepSeek transitioned from supervised learning to unsupervised learning, significantly reducing computational power and data costs. DeepSeek implemented a self-play mechanism for unsupervised models. For example, when asked a question, the model would generate 16 possible answers simultaneously, score each result based on predefined rules, and evolve in the direction of higher scores.
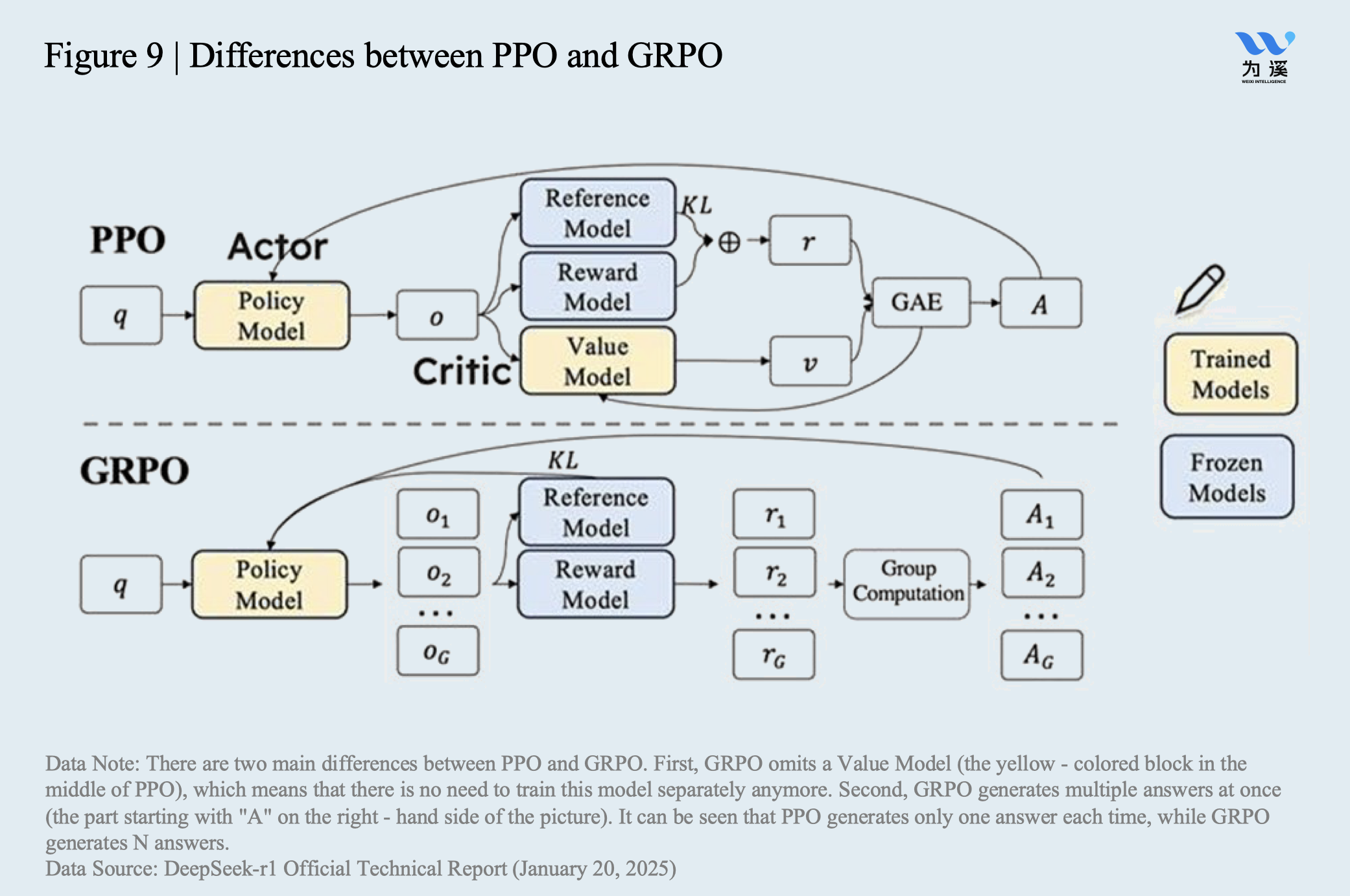
- Third Innovation: DeepSeek created an “upward spiral” model consisting of “foundational model → reasoning model → synthetic data → foundational model”. The R1-zero model, trained using the previous three steps with high-quality math and coding data as its core, showed limited generalization and expression abilities outside the fields of math and coding. To address this issue, DeepSeek first used R1-zero to generate long reasoning chain data beyond math and coding, along with high-quality, manually-labeled data, creating thousands of cold-start data sets with standard answers for the model to remember. Building on this, DeepSeek used R1-zero to generate 600,000 readable reasoning data and used foundational model v3 to generate 200,000 non-reasoning data (such as writing, factual Q&A, self-awareness, translation, etc.), allowing v3 to “fill in” reasoning chains for these non-reasoning data. These three types of data were combined into a synthetic data set of just over 800,000 entries (with only a few thousand manually-labeled entries). R1-zero continued to train on this data set, evolving into the R1 model that not only excels in math and coding reasoning, but also performs well in more general reasoning scenarios.
- Fourth Innovation: DeepSeek skipped the traditionally necessary standard fine-tuning (SFT) process and directly applied the above GRPO (Generalized Reinforcement Pretraining Optimization) architecture reinforcement learning to the foundational model (v3), iterating on the foundational model. As reasoning time increased during this self-play process, the model developed a self-questioning ability, referred to as the “Aha moment”. This is when the model, while solving problems, begins to ask itself, “Wait a minute, let’s think if there is a better solution?” In the iterative process of reasoning model improvement, it is astonishing to find that the reasoning chain shown by the model becomes longer and longer. More impressively, this is generated by the model itself, without external requirements, demonstrating the continuous improvement of the model’s reasoning ability.

- Finally, an important unfinished direction for DeepSeek is to continue to iteratively improve and integrate the foundational model through the reasoning model. OpenAI acknowledged this shift in a statement made on February 13, “Starting with GPT-5, there will no longer be a distinction between reasoning and foundational large models; o3 will be integrated into GPT-5.” With this, we can see that a path has formed, beginning with the foundational model, then transitioning to the reasoning model, and using the reasoning model to iteratively improve the foundational model.
02 | What is the essence of the innovation demonstrated by DeepSeek?
The essence of DeepSeek’s innovation can be summarized as follows.
First, in terms of pre-trained foundational large models, DeepSeek’s performance is comparable to top-tier large models, but at a fraction of their cost. This is made possible through engineering improvements in memory mechanisms, division of labor, and hardware communication mechanisms. Engineering innovation is not insignificant; in a sense, NVIDIA’s GPUs are also an engineering innovation, significantly improving the efficiency of what was once CPU-based serial computation through parallel computing mechanisms. Dario Amodei, CEO of Anthropic, stated, “DeepSeek’s innovation mainly focuses on engineering efficiency… The costs are much lower. The biggest difference this time is that the company demonstrating the anticipated cost reduction is a Chinese company.”
Second, in the realm of reasoning large models, DeepSeek’s creativity is even more original. The core of reasoning models is to build the ability to form reasoning chains, but the key is how to build it and at what cost. While many large model companies have failed to replicate OpenAI’s approach, DeepSeek focused on the most logically certain fields—mathematics and coding—to start. In this way, the model creates reasoning chains itself by learning correct answers over time, and then uses unsupervised learning methods to extensively explore and consolidate the reasoning chain methods needed for correct answers. This is a clever, low-cost innovation that bypasses the high-cost path of manually creating and labeling reasoning chains. After the R1-zero reasoning model was established in the math and coding domains, DeepSeek used a small amount of manually-labeled data to generalize it to a broader range of non-math and coding data, forming the R1 model. Finally, this process fed back into the foundational model, transforming the previous model training approach that required long periods and tens of millions of dollars into a more cost-effective iterative process. Thus, pre-trained models and post-training reasoning models complement each other, iterating together.
DeepSeek’s success can be attributed to consciously taking a path of low-cost innovation. First, it significantly reduced the cost of pre-trained foundational models through engineering innovation. Then, by breaking down tasks, DeepSeek explored the most cost-effective and flexible way to build reasoning chain capabilities in reasoning models.
To be fair, without the pioneering ideas of the most advanced U.S. large model companies, such as OpenAI, DeepSeek would not have achieved what it has today. What DeepSeek has done is to combine efficiency and innovation on the foundation laid by OpenAI’s direction.
This is the new path of AI innovation in China. Directly related to the restrictions Chinese companies face in computing power, DeepSeek has broken away from the inertia of U.S. companies relying on “brute force to make miracles”. In the U.S., where computing power is not scarce, economies of scale have been confused with the “brute force to make miracles” approach, underestimating the importance of innovation costs.
03 | Was DeepSeek’s innovation thus far inevitable or accidental?
The success of DeepSeek’s innovation marks a turning point in the AI industry, demonstrating that engineering innovation now holds significant value.
We have just discussed the type of disruptive innovation DeepSeek has achieved. Yet, is the success of this innovation accidental or inevitable?
Many have come to the understanding that breakthroughs in AI require top talent. Therefore, people are surprised that it wasn’t the “AI Seven Sisters” from the U.S. or China’s big tech giants, but rather DeepSeek, a quantitative hedge fund research team from China, that delivered such a stunning breakthrough. The more fundamental question is: What kind of capability is needed to lead breakthroughs in AI innovation?
Simply put, DeepSeek’s success proves that the AI industry has reached a stage where engineering innovation capabilities can now thrive.
To understand this logic, let’s look back at the key milestones that the AI industry has passed in the past two years.
It can be said that in the past few years, the two most important 0-to-1 groundbreaking advancements in the AI industry were both brought about by large model companies from the U.S., represented by OpenAI. OpenAI first proved to the world that using computational breakthroughs to pre-train data and build generative neural networks is an effective path to creating intelligence, demonstrated by the success of GPT. As a result, from the release of ChatGPT at the end of 2022, a series of pre-trained large models emerged.
But by the second half of 2024, when people were complaining that “pre-training has hit a wall” and “GPT-5 has not been released”, the reality was that pre-trained foundational large models struggled with complex problems, and the marginal improvements were limited. The second major breakthrough brought by OpenAI was to usher in the global AI industry into the era of reasoning models and reveal to the world that “the core secret of o1 is reinforcement learning”, providing the framework for post-training reasoning models with thinking chains.
At this point, the paths and frameworks for both pre-trained large models with fast (surface) thinking capabilities and reasoning large models with slow (deep) thinking abilities were clearly delineated. However, due to the high computational costs, actual usage rates are low. It is reported that by the end of 2024, the usage rate of o1 among ChatGPT users was less than 5%. The most important reason is the high technical cost—o-series pricing is expensive, requiring $200/month to support computational needs.
Thus, at this stage, the area with the most potential as a low-hanging fruit in the AI industry is actually the ability to dramatically increase efficiency “from 1 to 10” through engineering capabilities, thus promoting the widespread application of AI technology. U.S. companies, which have long benefited from advanced chips, have developed a reliance on “brute force to make miracles”, underestimating the value of efficiency improvements. However, in the context of limited computational power, Chinese AI companies are forced to prioritize the effective use of computational power as a necessary path for development. DeepSeek, with its strong engineering innovation capabilities, has taken this up. DeepSeek’s rise can be seen as “happening at the right time.” Its success is not accidental, but reflects the AI revolution heading into a phase where engineering innovation can reap the low-hanging fruit.
04 | What does DeepSeek’s innovative capability represent?
The success of DeepSeek is a strong indicator that Chinese-style engineering innovation can shape the entire AI industry. The deep engineering capabilities accumulated by Chinese companies in the manufacturing sector will also usher in a rapid golden phase in AI model research, development, and application.
While engineering innovation may not be as dazzling as 0-to-1 innovation, its impact on the industry is disruptive. DeepSeek’s outstanding performance demonstrates this potential. In fact, from chip efficiency, large model efficiency, the efficiency of combining large models with cloud computing, to the efficiency of AI industry application implementation, engineering innovation holds vast potential for upgrading effectiveness at every stage, thereby changing the scope for AI capabilities and product experiences. Chinese companies, with their manufacturing expertise, often possess the engineering innovation capabilities to excel in this field.
In this process, recognizing the immense value of engineering innovation and possessing an innovative mindset is a critical starting point. As DeepSeek’s founder Liang Wenfeng observed that “The cost of innovation is certainly not low, and the past inertia of ‘borrowing’ ideas is also related to our national conditions. But now, look at the scale of China’s economy, and the profits of big firms like ByteDance and Tencent — they are not low globally. What we lack for innovation is definitely not capital, but confidence and the knowledge of how to organize high-density talent to achieve effective innovation.”
Continue reading on CKGSB website
Enjoying what you’re reading?
Article Subscribe (1)
Professor profile

CHEN Long
Professor of Managerial Practice in Finance, Cheung Kong Graduate School of Business (CKGSB)
PhD, University of Toronto
Related Articles



Related Articles




Our Programs

Asia Start: AI + Digital China Expedition
Asia Start provides entrepreneurs and executives with unparalleled access to Asia’s dynamic digital economy and its business ecosystems, offering the latest trends and insights, strategies, and connections to overcome challenges and unlock future growth for your business in Asia and beyond.
LocationChina (Shanghai, Hangzhou, Shenzhen)
Date11 - 14 May, 2026
LanguageEnglish

Scaling Innovation: AI and Digital Strategies for Business Transformation
Global Unicorn Program Series
In partnership with Columbia Engineering
This program is designed to equip senior executives with the strategic insights and tools necessary to lead in this transformative era.
LocationNew York, USA
Date27 Sep - 02 Oct, 2026
LanguageEnglish

Emerging Tech Management Week: Silicon Valley
Global Unicorn Program Series
In partnership with UC Berkeley College of Engineering
This program equips participants with proven strategies, cutting-edge research, and the best-in-class advice to fuel innovation, seize emerging tech developments, and catalyse transformation within your organization.
LocationUC Berkeley
Date01 - 06 Nov, 2026
LanguageEnglish

Stanford & Silicon Valley Immersion Program
Global Unicorn Program Series
In partnership with Stanford Engineering Center for Global & Online Education
This CKGSB program equips entrepreneurs, intrapreneurs and key stakeholders with the tools, insights, and skills necessary to lead a new generation of unicorn companies.
LocationStanford University Campus,
California, United States
Date06 - 11 Dec, 2026
LanguageEnglish with Chinese Translation


